
🔔 아래 포스팅은 K.N.King 의 C Programming : A Modern Approach 2/e 의 17.5 Linked Lists 를 참고하여 작성하였으며 모든 예제 코드는 해당 도서의 예제 코드입니다! 🔔
연결 리스트
연결 리스트(linked list)는 '노드'라 불리는 구조들의 연결(chain)로 구성되어있고, 각각의 노드가 연결된 다음 노드를 가리키는 포인터(아래 그램에서의 화살표)를 포함하는 자료 구조이다. 연결 리스트에서 마지막 노드는 다음 노드가 없기 때문에 null 포인터를 포함한다. (아래 그림에서는 대각선으로 표시되어있음 )

연결 리스트의 장단점
여러 데이터들을 모아서 저장할 때는 일반적인 배열 뿐 아니라 연결리스트도 좋은 자료 구조가 될 수 있다. 연결리스트에서는 노드를 추가/삭제하기 쉽고, 원하는 만큼 크기를 키우고 줄이는 것이 쉽기 때문에 일반 배열보다 더 유연하다. 하지만 연결리스트에서는 배열의 임의 접근*(random access)을 사용할 수 없기 때문에, 리스트의 시작에 가까운 노드에 접근하는 것은 빠르지만 리스트의 끝에 가까운 노드에 접근하는 것은 느리다.
*임의 접근이란 배열의 인덱스를 사용해서 특정 원소에 바로 접근하는 것을 의미. 항상 O(1)의 시간복잡도를 가진다.
C언어로 연결리스트 구현하기
1. 노드 타입 선언
연결리스트를 만들기 위해서는 먼저 하나의 노드를 나타낼 수 있는 구조체가 필요하다. 연결리스트에서 필요한 노드는 값과 다음 노드를 가르키는 포인터 정보를 갖고 있어야 한다. 아래와 같이 node 구조체를 선언해보자.
struct node {
int value; // 노드에 저장되는 데이터(값)
struct node *next ; // 다음 노드를 가리키는 포인터
}위 코드에서 node는 struct node* 타입이라는 것에 주목해보자. 포인터는 다음 노드를 가리키기 때문에 가리키는 대상의 타입, 즉 struct node* 형이 되는 것이다. 이를 통해 한 가지 알 수 있는 사실이 있다. 구조체의 이름을 붙일 때는 태그를 사용하거나 typedef 이름을 사용하는데, 구조체가 동일한 종류의 구조체를 가리키는 멤버 변수를 가지고 있다면 항상 태그를 사용해야 한다. (typedef 이름은 사용할 수 없다!) 태그를 사용하지 않는다면 멤버 포인터 변수의 자료형을 명시할 방법이 없기 때문이다. 위 코드에서 구조체 이름 node를 쓰지 않고서 *next 의 자료형을 명시할 방법이 없다는 것을 생각하면 쉽게 이해가 갈 것이다.
이제 노드 구조체를 선언했기 때문에 리스트가 어디서 시작하는지를 추적할 수 있는 방법이 필요하다. 즉, 항상 리스트의 첫번째 노드*를 가리키고 있을 포인터 변수 하나가 필요하다. 이 포인터의 이름을 first 라고 할 때 아래와 같이 변수를 생성할 수 있다.
💡여기서 첫번째 노드란 가장 마지막에 생성된 노드를 의미한다! 가장 먼저 생성된 노드가 아니다 헷갈리지 말자! 노드가 왼쪽에서 오른쪽으로 차곡차곡 채워져 나간다고 생각하면 이해가 쉽다. 가장 마지막에 생성된 노드가 가장 왼쪽에 있는 노드, 즉 첫번째 노드이다!
struct node *first = NULL ;첫 번째 노드를 가리켜야 하는 포인터 first가 NULL 을 가리키고 있다. 이는 현재 리스트가 최초에 비어있는 상태를 나타낸다.
2. 노드 생성하기
연결리스트를 생성하려면 노드를 하나씩 만들고, 각각의 노드를 리스트에 더해주어야 한다. 노드를 생성하는 방법은 아래와 같다.
1. 노드를 저장할 메모리 할당
2. 노드에 데이터(값) 저장
3. 노드를 리스트에 삽입
메모리 할당
노드를 생성할 때, 생성한 노드를 리스트에 삽입하기 전까지 노드를 가리키고 있을 임시 변수가 필요하다. 이 변수의 이름을 new_node 라 하자. 이 변수에 메모리를 할당하기 위해서 malloc 함수를 사용하여 반환 값(할당된 메모리 주소 또는 null) 을 new_node에 저장해보자.
new_node = malloc(sizeof(struct node));데이터(값) 저장
new node는 임시로 만들어 둔 포인터 변수이다. 이제 new node가 가리키는 (진짜 내가 생성하려고 하는) 노드의 멤버 변수 value 값을 저장해보자. 아래 코드를 실행하면 아래 그림과 같은 상황이 되는 것이다.
(*new_node).value = 10;
// 또는 arrow 연산자를 사용해서 아래와 같이 쓸 수도 있음 (위 코드와 아래 코드는 동일한 의미)
new_node->value = 10;
리스트에 노드 삽입
연결리스트의 장점 중 하나는 노드가 리스트의 어떤 위치도 삽입될 수 있다는 것이다. 리스트의 앞이던, 중간이던, 끝이던 다 문제 없이 삽입할 수 있다. 그래도 리스트의 맨 처음에 노드를 삽입하는게 제일 쉽긴 하므로 이 과정을 먼저 해보자.
위에서 만든 new_node가 가리키는 노드가 리스트의 맨 처음에 삽입된다고 해보자. 이 노드 첫 노드이므로 리스트에 삽입된 후에 가리킬 다음 노드는 없다. 따라서 first가 가리키던 NULL을 이제는 노드의 next가 가리키게 해야 한다.
new_node->next = first ;
이제 리스트의 첫 번째 노드를 가리켜야 하는 first 노드는 삽입하려고 하는 노드를 가리켜야 한다. new_node의 값은 삽입하려고 하는 노드의 주소이므로, first 노드에 new_node 값을 대입하여 first 노드가 삽입하려고 하는 노드를 가리키게 한다.
first = new_node;
이제 새로운 노드가 삽입될 때 마다 위의 과정을 반복하면 된다.
new_node = malloc(sizeof(struct node)); // 새 노드에 메모리 할당
new_node->value = 20; // 삽입할 노드에 값 저장
new_node->next = first // 삽입할 노드의 next(다음 노드 포인터)로 first(직전에 삽입된 노드) 대입
first = new_node // first로 new_node의 값(새로 삽입한 노드의 주소)을 대입
노드를 삽입할 때마다 수행해야 하는 코드들이므로, 이를 함수로 만들어서 수행하는 게 좋을 것이다. 연결리스트의 시작을 가리키는 포인터와 새 노드에 삽입할 값 n을 인수로 받는 함수를 생성하면 아래와 같다.
struct node *add_to_list(struct node *list, int n)
{
struct node *new_node;
new_node = malloc(sizeof(struct node));
if (new_node == NULL) {
printf("Error: malloc failed in add_to_list\n");
exit(EXIT_FAILURE);
}
new_node->value = n;
new_node->next = list
return new_node;
}위 함수는 첫 번째 인수로 받은 포인터 (첫번째 노드를 가리키는 포인터)를 수정하지 않는 대신, 새롭게 생성된 노드를 가리키는 포인터를 리턴한다. 그래서 위의 함수를 호출할 때, 함수가 반환한 값을 first로 저장해서 다음 노드를 생성할 때 인자로 써야 한다. (아래 코드 참조)
first = add_to_list(first, 10);
first = add_to_list(first, 20);위와 같은 방식이 아니라 함수가 직접 first 변수를 업데이트하게 하는 것은 다소 까다롭다. 이는 추후 따로 다루도록 하겠다.
이제 위의 add_to_list 함수를 활용하여 입력받은 값을 포함하는 연결리스트를 만들어 내는 함수를 생성해볼 수 있다.
struct node *read_numbers(void)
{
struct node *first = NULL;
int n ;
printf("Enter a series of integers. Enter 0 in order to terminate. : ");
for (;;) {
scanf("%d", &n);
if (n==0)
return first ;
first = add_to_list(first, n) ;
}
}앞서 말한 것과 같이 first는 항상 가장 마지막에 입력된 노드를 가리키고 있기 때문에, 위의 함수에서 입력한 정수들은 반대의 순서를 (늦게 입력한 정수가 더 먼저 나오는) 갖게 된다는 점에 유의하자.
연결리스트 검색하기
연결리스트를 생성하였으니 특정 데이터를 검색하는 기능을 구현해보자. 연결리스트의 검색 기능을 구현할 때는 while문보다 for 반복문이 (counting을 포함하고 있다는 점 뿐만 아니라, 유연하다는 점(flexibility)에서) 더 우수하다. for문을 사용해서 연결리스트의 노드들을 방문하는 관례적인 코드는 아래와 같다.
for (p=first; p!=NULL; p= p->next) {
...
}위 코드는 한 줄로 첫 번째 노드를 가리키는 포인터 변수 p, p의 값이 NULL이 아닐때, 현재의 p를 다음 노드로 바꿔주는 조건을 모두 담고 있다. 이러한 방식은 연결리스트를 순회하는 반복문을 작성할 때 변함없이 사용되는 형식이다.
이를 활용하여, search_list라는 연결리스트 검색 함수를 작성해보자.
struct node *search_list(struct node *list, int n)
{
struct node *p;
for (p= list; p!=NULL; p = p->next)
if (p->value == n)
return p;
return NULL;
}위 코드는 첫번째 노드(가장 마지막으로 삽입된 노드)를 가리키는 노드를 인수로 받아 해당 노드가 가리키는 노드의 값과 n을 비교한다. 값이 같으면 해당 노드를 가리키는 노드를 리턴하고, 끝까지 순회했음에도 불구하고 n과 일치하는 노드를 찾지 못하면 NULL을 반환한다.
이 외에도 연결리스트를 검색하는 함수들은 다양한 형태가 있지만 여기서는 다루지 않도록 하겠다. (궁금하신 분들은 C Programming : A Modern Approach 430p를 참고하시면 됩니다)
연결리스트에서 노드 삭제하기
연결리스트로 데이터를 저장하는 가장 큰 이점은 노드의 삭제가 간편하다는 것이다. (일반적인 배열에서는 원소를 하나 삭제하면 나머지 원소들을 모두 한칸씩 앞으로 옮겨야한다. O(n)의 시간 복잡도이다) 연결리스트의 노드 삭제는 아래의 세 가지 단계를 거친다.
1. 삭제할 노드의 위치로 이동.
2. 삭제할 노드의 이전 노드가 삭제할 노드를 우회하도록 수정.
3. 삭제한 노드가 차지하던 메모리를 비우기 위해 free 함수 호출
삭제할 노드의 위치로 이동
이 단계는 보기보다 어렵다. 삭제할 노드의 위치로 가기 위해 연결리스트에서 삭제할 노드를 검색한다면, 우리는 삭제할 노드를 가리키는 포인터에 도달할 것이다. (연결 리스트 검색 함수는 찾는 값을 가진 노드를 가리키는 포인터를 반환하기 때문) 하지만 이렇게 되면 우리는 2번 단계, 즉 삭제할 노드의 '이전' 노드를 수정할 수가 없다는 문제가 생긴다. 이전 노드를 가리키는 포인터는 우리에게 없기 때문이다. 이를 해결하기 위해 이전 노드를 가리키는 포인터와 현재 노드를 가리키는 포인터를 둘 다 사용하는 'trailing pointer' 기법을 사용할 수 있다. 아래 코드를 보자.
*이전 노드를 가리키는 포인터가 현재노드를 가리키는 포인터를 계속 쫒아다니기(trailing) 때문에 trailing pointer 라는 이름을 가진다.
/*
prev : 이전 노드
cur: 현재 노드
list: 연결리스트의 첫 번째 노드를 가리키는 포인터
n: 삭제해야 할 값
*/
for(cur= list, prev=NULL; cur!=NULL && cur->value!=n ; prev=cur, cur=cur->next){
...
}위 for문 내에서 우리가 n을 찾기 위해 필요한 모든 과정이 다 담겨있다. 이 for 반복문이 종료될 때 cur 는 삭제할 노드를 가리키고 있을 것이고, prev는 이전 노드(가 있다면)를 가리키고 있을 것이다. 이 반복문의 실행과정을 짚어보기 위해, list 변수가 30, 40, 20, 10 값을 포함한 노드(list)를 순서대로 가리키고 있는 상황을 생각해보자.

만약 삭제할 값(n)이 20이라면, 우리는 세 번째 노드를 삭제해야 한다. cur= list, prev=NULL; 이 실행되어 반복문의 초깃값이 설정되고 나면 cur은 첫번째 노드를 가리키고 있을 것이다. (아래 그림 참고)
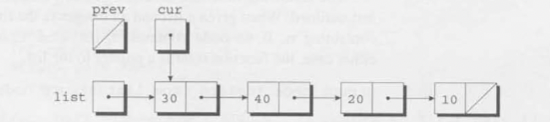
조건문 cur!=NULL && cur->value!=n ; 은 참 이므로, 증감문 prev=cur, cur=cur->next; 이 실행되어 prev와 cur은 새로운 값을 갖게 된다. 이러한 방식으로 prev는 항상 cur 의 뒤를 쫒아다닌다(trailing)는 것을 볼 수 있다.
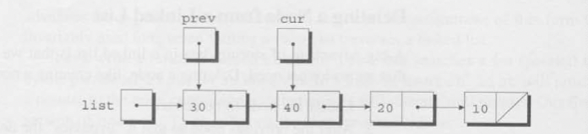
조건이 참이므로 반복문의 다음 루프가 실행되고 증감문이 실행된다. 이제 prev는 두번째 노드를 가리키고, cur은 세번째 노드를 가리킨다.
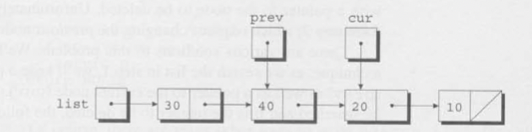
이제 cur이 가리키는 노드의 값은 n이므로 cur!=NULL && cur->value!=n ;는 거짓이 되고 반복문은 종료된다. 이제 우리는 삭제할 노드의 이전 노드가 삭제할 노드를 우회하도록 수정하는 두번째 단계를 시작할 수 있다.
삭제할 노드의 이전 노드 수정
삭제할 노드의 다음 노드가 삭제할 노드의 다음 노드가 되도록 하면 이전 노드를 우회할 수 있다. 아래 그림에서 두번째 노드의 다음노드가 네번째 노드가 되게 하면 세번째 노드는 연결리스트에서 빠지게 된다.
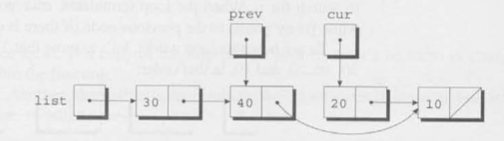
아래의 코드로 이를 구현할 수 있다.
prev->next = cur->next;
삭제한 노드가 차지하던 메모리 반환
이제 삭제할 노드가 차지하던 메모리를 반환하여 나중에 다시 사용될 수 있도록 해야 한다. free 함수를 사용하자.
free(cur);
위의 단계를 함수로 구현하면 아래와 같다.
struct node *delete_from_list(struct node *list, int n)
{
struct node *cur, *prev;
for(cur= list, prev=NULL;
cur!=NULL && cur->value!=n;
prev=cur, cur=cur->next)
{
if (cur==NULL)
return list; // n을 찾지 못한 경우
if (prev==NULL)
list = list->next; // n이 첫번째 노드에 있는 경우
else
prev->next = cur->next; // n이 나머지 노드 중에 있는 경우
free(cur);
return list;
}
}
Reference
1. C Programming : A Modern Approach, 2/E K. N. King | W. W. Norton & Company
'C' 카테고리의 다른 글
| [C] 메모리 할당 - 동적 메모리 할당 (김성엽의 기초 C언어 강좌 16장 2) (0) | 2022.10.28 |
|---|---|
| [C] 메모리 할당 - 정적 메모리 할당 (김성엽의 기초 C언어 강좌 16장 1) (0) | 2022.10.28 |
| [C] 문자열 리터럴 (문자열 상수) | 문자열 리터럴의 저장, 포인터, 문자열 변수와 문자열 상수 (2) | 2022.10.23 |
| [C] 배열과 포인터 | 포인터와 배열의 관계, 배열 이름을 포인터처럼 사용하기, 포인터를 배열의 이름으로 사용하기 (0) | 2022.10.22 |
| [C] 포인터 | 포인터란, 포인터 변수의 선언/초기화/호출, &연산자와 *연산자, 포인터의 연산, 포인터에 자료형이 필요한 이유 (0) | 2022.10.22 |




댓글